
Recent Updates
TL; DR
We calculate Branch Divergence as
foreach b in repo r; D = DSB.days * (DSB.days - DSLC.days)where DSB is Days Since Branch and DSLC is Days Since Last Commit.
We quantified divergence, eliminated technical debt and accelerated development velocity. This post summarizes the details of how we at Nebulaworks solved a big problem together.
Introduction
I spent some time with Rob Hernandez, CTO of Nebulaworks to discuss the challenges of diverged branches, our quantification of the problem with the python script, and his thoughts on the benefits of Trunk Based Development Workflows (“TBD Flows”). What follows is a rough transcript of my conversation with Rob.
At the end of this post, we’ll share our lessons learned, takeaways and best practices, along with the code.
The Challenges of Diverged Branches
Rob, what problem was Nebulaworks trying to solve?
A particular client had a lot of diverged branches and some of them had become authoritative for the specific parts of the codebase. We needed to quantify the problem so we could convey the magnitude of the situation and why it is worth correcting the problem.
What are diverged branches and why are authoritative diverged branches a problem?
In computer science, a computation is said to diverge if it does not terminate or it terminates in an exceptional state. Branch divergence happens when there are multiple authoritative branches in the repository.
So, we define divergence as not only a branch being ahead and behind, but also authoritative?
Yes, this is correct, this is the exceptional state as it’s defined in computer science terms.
Say, for example, Feature C and Feature D are implemented on top of A and B, but only branch C is merged. Now the authoritative branch (the trunk) has ABC, but not D. While branch D is both ahead and behind, we define it as diverged when it becomes an authoritative source of new features (i.e it is deployed to production).
This makes sense. So what did you find after running the report?
We found 30+ branches that had diverged. This meant that a developer would have to comb through 30+ exceptional branches to identify the branch was authoritative for the new changes being made to the codebase
Because so many branches have deviated from the trunk, we’ve had to take the approach that the only way out was to merge all 30 branches carefully. Once we get them all sorted out, we would circle back on the best path forward for the features and whether or not they actually still made sense in the codebase. Remember many of these branches also did not have any kind of peer review.
The complexity was getting so bad that these specific diverged parts of the codebase restricted the future functionality and feature set. It was even up for consideration to scrape the codebase and start fresh since people were becoming demotivated with the current repo state.
Is Nebulaworks untangling this for the customer?
Yes, we are. It is paramount that we have all of the code landing in the main/trunk branch so that we can continue to move the collective codebase forward. This also enables the wider team to be able to operate at a high level because the workflow is clear and ubiquitous for all changes being made.
The solutions that we are building within the customer’s environment are complex enough, having to figure out how to merge this code should not be added to that complexity.
Quantifying The Problem of Branch Divergence
It was quite clear to me that the implications of diverged branches has may implications. Before diving into those details, I asked Rob about the formula itself.
Rob, tell me about the formula; you had a clear idea of how you wanted D to be calculated.
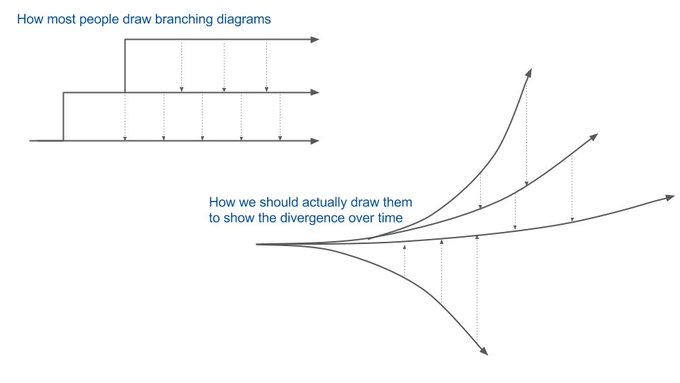
The branch illustration from Jonny LeRoy below explains it well. The longer in time a branch is diverged from the mainline, the harder it is to pull it back in. We needed a simple calculation to quantify the problem.
Can you show us an example of the output of the report?
Repo at /home/vihar/Documents/remote/gitlab/redacted successfully loaded.
Repo description: Unnamed repository; edit this file 'description' to name the repository.
Remote named "origin" with URL "git@gitlab.com:nebulaworks/redacted.git"
Branch Behind Ahead DSB DSLC DIVERGENCE
origin/Branch1 263 111 226 85 31866
origin/Branch 531 42 226 149 17402
origin/JIRA-1 947 31 204 136 13872
origin/TOPIC-2 616 15 196 148 9408
origin/ab/DEV-7 170 2 70 70 0
...
This is a redacted example with many of the branches removed for brevity. One can see the report gave us what we needed to triage the divergence.
Take a look at some of the most long lasting, open source code repositories on the internet. For example, look at the linux repo or the FreeBSD repositories. Especially in the case of linux, there are over 11K contributors and almost 1M commits, all merged into a single, clean trunk called master.
The etiquette of trunk based workflows, clean commit history and allows all of these developers to collaborate effectively and easily.
As a bespoke software development shop, Nebulaworks promotes a trunk based software development workflow.
Trunk Based Workflows for Software Development
Rob, tell us more about Trunk Based Workflows for Software Development?
Trunk based software development has been around for a very long time. I like to think it’ll one day be considered a pillar of good software development habits. It provides a very clear set of workflow “rules” which promotes a single source of truth for the entire codebase being the trunk (master) branch. We do everything we can to ensure that before a working branch makes it way into the trunk that it is tested, working as intended, and its history is atomic. This way we ensure the business can deploy anytime it sees fit, no matter how fast or slow.
Where can readers learn about TBD workflows?
Take a look at our post written by Matthew Ramirez on Trunk-Based Development for Beginners. This is a good place to get started.
Lessons Learned
Although Rob had asked for the report with a simple formula, I could not help but wonder if there was more to it than
just D = DSB.days * (DSB.days - DSLC.days). Surely the number of commits both ahead and behind impacted divergence.
Rob, the calculation used for divergence was quite simple. Could it be improved upon?
As a reminder, we started out with the simple calculation:
foreach b in repo r; D = DSB.days * (DSB.days - DSLC.days)
We could have improved on the calculation, but we found after our initial run was that we had 30 branches to deal with. We did the minimal amount of work to quantify the problem. We know it gets worse the longer it goes and the more authoritative the diverged branch becomes.
The objective though was to quantity the problem and couple this with what we knew about divergence.
What’s next Rob now that you’ve got the code unwound?
We’re not done yet. We were able to make some really good strides forward and have cleaned up the most diverged branches from our results. The remaining branches we will get to once some of the other priorities get wrapped up.
More importantly, we are committed to training and defining a culture where everybody wins with a properly aligned and incentivized software development methodology like trunk based development. By using the metrics from the Divergence report, we are able to create a culture where software development is accelerated and creative.
Takeaways
Where can development teams that are dealing with branch divergence start?
The best place to start is at our website. We have a lot more information about what we do as well as more posts on software development. Other good sources of information are:
Best Practices
Rob, what is the one best practice that readers of this blog post can walk away with?
We at Nebulaworks have been saying the same thing for many years now; start with trunk based development as your development methodology. It provides a simple, proven foundation that you can iterate on over time. If not, somebody has to pay the piper for technical debt reduction when the repo becomes untenable.
Python Script Details
The script itself was non-trivial to implement; it relied on the gitpython for object processing. The provided tutorial and stub code were well written and acclerated the development. We added a few other constants given our specific use case.
import datetime
import os
import re
import sys
from git import Repo
MASTER = "master"
DATETIME = "%Y-%m-%d %H:%M:%S%z"
BRANCH_FILTER = r"(.*RC\/.*)|([0-9]+\.[0-9]+\.[0-9]+\.[0-9]+)"
def get_first_commit(repo, branch):
other_shas = set()
first_commit = None
for parent_commit in repo.iter_commits(MASTER):
other_shas.add(parent_commit.hexsha)
for commit in repo.iter_commits(branch):
if commit.hexsha not in other_shas:
first_commit = commit
return first_commit
def get_divergence_report(repo):
report = []
for head in repo.refs:
br = str(head)
if re.match(BRANCH_FILTER, br):
continue
a, b, dslc, dsb, d = divergence_by_branch(repo, br)
if a:
row = {
"Branch": br,
"Behind": b,
"Ahead": a,
"DSB": dsb,
"DSLC": dslc,
"Divergence": d,
}
report.append(row)
return sorted(report, key=lambda k: k["Divergence"], reverse=True)
def divergence_by_branch(repo, branch):
latest_commit = repo.commit(branch)
first_commit = get_first_commit(repo, branch)
a = list(repo.iter_commits(MASTER + "@{u}.." + branch))
b = list(repo.iter_commits(branch + ".." + MASTER + "@{u}"))
c = latest_commit.authored_datetime
d = datetime.datetime.now(tz=c.tzinfo)
DSLC = d - c
e = repo.commit(first_commit)
DSB = d - e.authored_datetime
D = DSB.days * (DSB.days - DSLC.days)
return len(a), len(b), DSLC.days, DSB.days, D
def print_commit(commit):
print(str(commit.hexsha))
print(
'"{}" by {} ({})'.format(
commit.summary, commit.author.name, commit.author.email
)
)
print(str(commit.authored_datetime))
print(
str("Commit count: {} and Commit size: {}".format(commit.count(), commit.size))
)
def print_heads(repo):
for head in repo.heads:
print('Repo Head named "{}"'.format(head))
def print_repository(repo):
print("Repo description: {}".format(repo.description))
for remote in repo.remotes:
print('Remote named "{}" with URL "{}"'.format(remote, remote.url))
def main():
repo_path = os.getenv("GIT_REPO_PATH")
if repo_path is None:
print(
"GIT_REPO_PATH not set. Export GIT_REPO_PATH=/path/to/git/repository and try again."
)
sys.exit(0)
try:
repo = Repo(repo_path)
except:
return []
if repo.bare:
print("Could not load repository at {} :(".format(repo_path))
repo.config_reader()
print("Repo at {} successfully loaded.".format(repo_path))
print_repository(repo)
report = get_divergence_report(repo)
table = "{:32} {:^8} {:^8} {:^4} {:4} {:8}"
print(table.format("Branch", "Behind", "Ahead", "DSB", "DSLC", "DIVERGENCE"))
for b in report:
print(
table.format(
b["Branch"],
b["Behind"],
b["Ahead"],
b["DSB"],
b["DSLC"],
b["Divergence"],
)
)
return report
if __name__ == "__main__":
report = main()